Implementing cookie consent with “Content Security Policy”
In this post I briefly explain how “Content Security Policy” could be used to enforce the cookie consent regulation by blocking third parties content…
In this post I briefly explain how “Content Security Policy” could be used to enforce the cookie consent regulation by blocking third parties content…
Google most important privacy policy changes happen almost two years ago. The change was announced as a clarification of the policies which will mainly be used to simplify and improve services. Now that the changes are effective, it is interesting to observe what the consequences of the new policy are and what has changed. In this blog post I focus on Google tracking capabilities and show that the changes allow Google to improve significantly the way it tracks users on the web.
The claim about DoubleClick cookie information
One of the few protective claims Google made in its policy was that “[they] will not combine DoubleClick cookie information with personally identifiable information unless we have your opt-in consent”. Some understood that Google would not combine information from the Google Account with information from DoubleClick ad-network, but that was not the case.
Using information from the Google profile
As a matter of fact, Google has so far combined many pieces of information from its ad network with information obtained from Google profiles. Your age and gender have already been shared with DoubleClick advertisers for many months now as shown on Google Ads Setting page. At the beginning, these data were shared on an opt-in basis through the “+1 personalization page”. It was not obvious that his page controlled how information from your profile was shared with advertiser as this was only mentioned as “+1 and other profile information”.

The “+1 personalization” (see below) page has been removed when Google announced “ad endorsement” and now the URL of the page redirects to the ad-endorsement page. As a matter of fact, it is no longer possible to opt out of ads on the web be based on your Google profile without opting out of all interest based ads.

This change came with no announcement, because the privacy policy only prevents Google from combining PII from the Google profile.
Ad customization based on visited website
The policy does not prevent Google from associating your visits on websites affiliated to DoubleClick to target your Google profile. As a matter of fact, your Google account can be retargeted by DoubleClick affiliated websites you visited. This feature — called Remarketing list for search ads – lets advertisers retarget previous visitors on Google Search.
Technically, Google cannot recognize when a user visited a site web affiliated to DoubleClick because the domains associated to the cookies are different. When you’re doing a search on Google, Google reads only cookies attached to “google.com” domain, whereas on Google Display Network (i.e. the set of websites with DoubleClick ads) cookies are attached to the doubleclick.net domain. Google knows the DoubleClick cookie ID of people who visited a website on Google Content Network but it does not know their Google ID. This is problematic because when you do a search on Google, you do not reveal you DoubleClick ID but just your Google ID. So when you do a search, Google cannot know if you’ve visited a website which does retargeting.
To solve this, Google redirects your browser from the doubleclick.net domain to the google.com domain. When you visit a website which wants to retarget you, DoubleClick redirects you to google.com domain and Google adds your Google ID to the list of persons who visited the advertiser’s website. Next time you’ll do a search Google will recognize your Google ID and retarget you with ads for the website you visited. The figure bellow explains how Google records that a user visited the website ABC (you can capture the actual frames on worldstore.co.uk).

Through this process, Google associates the list of websites affiliated to Google Display Network (it means with a DoubleClick tag) you visited to your Google ID. Consequently, part your web browsing history (the part containing websites which do remarketing) is actually combined to your Google profile and you cannot review it. Notice that Google never proposed a way to know which website you visited and try to retarget you, but while Google could have claimed that your browsing history was only associated to you “anonymous” DoubleClick ID, it is now attached to your personal Google account.
To summarize, Google cannot combine personally identifying information from your Google account with you DoubleClick cookie information, yet it can:
– Use information from your Google account (age, gender and probably very soon a list of your interests) to personalize ads that you see on DoubleClick affiliated website
– Link visits on DoubleClick affiliated websites to your Google profile and retarget you when you do a search on Google.
In the end, Google privacy policy with regard to advertising is well summarized on this page:
In the next page, I consider how Google combines information from Google profile and DoubleClick with data obtained though Google Analytics.
Update: Facebook started to show the announced prompt and ask for user consent.
Almost a year after it removed the option for 90% of its members, Facebook informed on Wednesday the remaining 10% that they’ll remove the “Who can search my timeline by name” setting in a few days. Removing this setting si likely a violation of the 2011 FTC settlement.
A month ago Facebook announced that they’ll prompt user to get their consent before removing the setting [1] but they finally decided to just inform users with an email and a very short notice displayed above the News Feed.
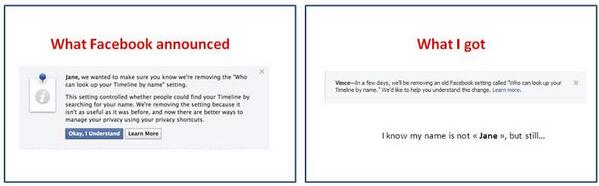
In the mail sent to its members, Facebook argues that when they created this setting “the only way to find [them] on Facebook was to search for [their ]specific name. Now, people can come across [their] Timeline in other ways: for example if a friend tags [them] in a photo, which links to [their]Timeline, or if people search for phrases like “People who like The Beatles,” or “People who live in Seattle,” in Graph Search”. However, I’m confident that some users – including me — are not tagged in public photo, do not like public content and have no friend whose “friends list” is public.
Timelines of these users will not appear in public Graph Search results Facebook and there is no public link that could be used to find them. As a matter of fact, people who are not my friends (or friends of friends) can’t even know if I have a Facebook account. As for today, the only solution to find my Facebook Timeline is to test the 1.2 billion userID numbers. In addition to be time consuming, this exhaustive search would violate Facebook Terms of Services.
A Timeline page is public because any user can load its content but Timelines URLs (i.e. usernames) are not public since not anyone can find them: without the search functionality, it is not possible to retrieve the Timeline associated to a specific user. Timelines URLs are like unlisted phone numbers or Google Docs shared with “anyone with the link”. These documents may not be seen as private but I would not define them as public (i.e. I’d be unpleasantly surprised to see them used in an endorsed advertisement). I do not claim that Timelines are private, only that they are “nonpublic user information” .
The FTC settlement does not focus on user private information but cover the entire nonpublic user information (e.g. a user ID to which access is restricted by a privacy setting). Indeed, Section II-A of the 2011 settlement requires that Facebook “prior to any sharing of a user’s nonpublic user information by [Facebook] with any third party, which materially exceeds the restrictions imposed by a user’s privacy setting (s), shall […] obtain the user’s affirmative express consent”.
Facebook will not only remove the possibility to select who can look-up timelines, they will set the setting to its default values “Everyone”. Hence, Facebook will modify settings of users who set it to a more restricted audience. Obviously the two lines message Facebook displayed and the email they sent to the affected members does not offer a valid solution to get an affirmative express consent. So Facebook will certainly violate the FTC settlement in a few days.
[1] Coincidentally, Facebook made this announcement about 5 hours after I tweeted that they should get an informed consent.
According to Facebook, Graph Search not only helps people finding information about their friends, it also helps them to know what information they reveal about themself. I find this objective questionable especially in France where many people are still not aware that Graph Search even exist [1] and yet have their profiles searchable by anyone in the US. Yet, Graph Search is certainly very useful and educative about what could go wrong with tagging and shared content.
When Facebook announced Graph Search in January, I was surprised by their decision to not show friends lists that could be recomposed by browsing timelines. Recomposing part of someone friends list was time consuming but possible if you spent time scrolling down the timeline.
Last July update of Graph Search makes it even simpler to retrieve list of friends of people who hide it. Indeed, Graph Search now allows you to search who liked or commented on photos. Since some content is only visible to my friends, only they can comment or like my pictures. Having a list of people who liked or commented on my photos is like having a list of my friends with who I share things on Facebook. Some people that I do not know commented on my photos, but that’s a negligible fraction.
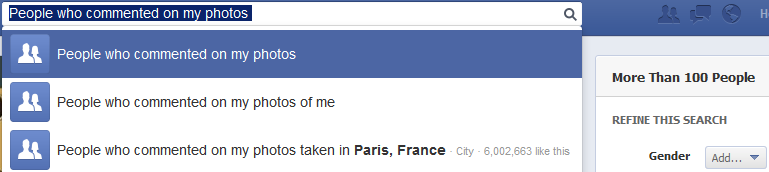
Surprisingly, it seems that you can even know if someone liked a photo you don’t have access to. Indeed, in some circumstances, you cannot see which picture has been liked; you only know that someone liked a picture (see bellow). It goes against Facebook claim that Graph Search only gives you access to information you already had.
Update: In fact, the person who liked the picture is not searchable but she appears in the search results because she liked a public photo.

Another annoying effect is that queries like “People who liked photos by me” returns a list of people with who I’m no longer friend. And it’s pretty easy to spot these people because they are systematically at the end of the result list.
To measure the fraction of the friend list that could be retrieved through Graph Search, I listed the number of results that were listed when I search for:
Unfortunately, Graph Search does not (yet?) support ‘OR’ queries so there is no easy way to quantify the overlap between these four queries . I reported numbers of confirmed retrieved friends (using the “mutual friend” filter) and the total number of retrieved people because it also includes former friends. I compare that to the number of friends I have (and I thank my friends who did not hide their friends list).
| X | Q1 | Q2 | Q3 | Q4 | N Friends | Ratio |
| me | 59 ( 73) | 43 (45) | 42(54) | 19(20) | 207 | 28.50% |
I made some tests on a few friends and I obtained similar results [2], queries Q1 and Q3 are the more effective queries in general. On average, Graph Search returns 30% of friends, plus some former friends. I guess I could retrieve up to 40-50% by combining the four queries. It’s problematic because many people assume that their friend’s lists are safe, but this safety goes away when they share likable photos or when they like photos.
Since “Like” visibility is public, you can even retrieve some friends of people with who you have no connection. I can imagine many circumstances where having your list of friends publicly available is very problematic.
Unfortunately, you cannot prevent your friends from liking content you share with them. Likes are not like tag or comments: they cannot be removed. The only current solution is to not share “likeable” content or to ask to people to not like it, but that’s very counter intuitive on Facebook. In the end, you can only hide friends who don’t “like” you.
Another solution is to obfuscate the list of people who liked your pictures. I probably rely too much on obfuscation, but asking people you don’t know to like your photos is currently the only technical solution to prevent stalkers from quickly retrieving your friends.
Acknowledgements: Thanks to my stalked friends who do not share their friends lists, they motivated this post. Thanks to those who do share their list, they helped me to make this post relevant.
[1] If you have not yet enabled “Graph Search”, I recommand you to do so. See http://www.fredzone.org/comment-activer-le-graph-search-de-facebook-929
[2] I’ll post more results when I’ll get their consent
Google new privacy policy will be effective starting March the 1st. The Electronic Frontier Foundation (EFF) suggests to delete your Web Search History, and I strongly recommend to follow this advice because:
1) The searches that have been recorded in your Web Search History before March the 1st will be subject to this policy [1].
2) Advertisers could target ads based on your browsing interests and interests inferred from your Web Search History.
First, I have to say that Google did a remarkable job advertising the new policy: notifications are everywhere. I don’t remember any of the policy updates being that much advertised and then commented.
Another good point is that many privacy policies have been merged in one privacy policy. It is no longer required to have a dozen tabs opened to have a good view of the policy. However, you still need to have an extra tab on the FAQ page with the definitions required to understand the Policy. Google could have used the empty space in the right column to display these definitions (like search result previews).
So much for the good points, now let’s discuss the policy itself. The bottom line is this policy would allow advertisers target you based on your web search profile and other interests you expressed in your emails or through your use of Google services. And this list of interests can be combined with the list of interests they built based on your DoubleClick cookie.
Google does not need our Opt-in consent to combine your web search profile to your DoubleClick cookie information. Starting March the 1st, Google could adopt a solution similar to what is deployed by Microsoft to target ads based on your search interests, although a sentence in the policy seems to prevent such use of your data:
“We will not combine DoubleClick cookie information with personally identifiable information unless we have your opt-in consent.”
In fact, it means that your Double-Click cookie will not be linked to your personally identifiable information. So Google can not put your name in front of the list of interests they inferred from your browsing behavior and will not put your name (or any other PII) in the ads you see. Because your Web Search history is likely to be unique, it identifies you and therefore can not be combined to your DoubleClick profile [2].
But your search profile (i.e. the list of interests inferred from your search history) is unlikely to be unique and therefore does not identify you so Google can combine it with your DoubleClick cookie information [2]. I believe they could also include some the of search results you clicked on to retarget you.
Similarly, your age, gender and interests expressed during Gtalk and Gmail discussions (or any other interest that Google could infer but that you would not be the only one to express) could be associated to your DoubleClick cookie. If you have any suggestion to deal with these data, do not hesitate to share it.
[1] See Google Policy FAQ: “Our new Privacy Policy applies to all information stored with Google on March 1, 2012 and to information we collect after that date.”
[2] Google defines Personal information as information “you provide to us which personally identifies you, such as your name, email address or billing information, or other data which can be reasonably linked to such information by Google”.
After finding an information leakage in Google Search, I’ve been curious to see if there were no other pieces of information that could be gleaned from other Google services. To verify this, I visited my Google Dashboard, replaced my SID cookie and clicked on all the HTTP services that were listed.
My first attempt failed as I was systematically redirected to the account page where I was asked to enter my password. I then tried to also spoof the HSID cookie — also sent clear text — but because HSID cookie is an HTTPOnly cookie [1], it cannot be modified by a script or by the user: the cookie can only be modified by the server.
The best solution I found was to install a local proxy to intercept the HTTP traffic and then modify the cookies (I recommend Burp free edition which does a good job). It is then quite simple to replace the HSID cookie in the sent requests.
This time it worked, I was able to log into two services under with the spoof account:
There might be other vulnerable services but I think this list is already quite exhaustive and each of the listed service is likely to provide sensitive information.
Spoofing an unsecured cookie to hijack a session is nothing new. Nevertheless, there are two design flaws that HSID and SID cookies spoofing more critical:
Google is working on these issues and they should be fixed soon (users are already redirected to encrypted search [2]). Therefore, a next step would be to check if other major Web service providers have a better cookie policy.
Reference:
[1] Jeff Atwood, “Protecting Your Cookies: HttpOnly”, http://www.codinghorror.com/blog/2008/08/protecting-your-cookies-httponly.html
[2] Evelyn Kao, “Making search more secure”, http://googleblog.blogspot.com/2011/10/making-search-more-secure.html
In our paper on Google’s session cookie information leakage, Vincent Verdot and I described how to captures SID cookies on a shared network and run the attack with Firesheep (see the previous post).
Nevertheless, there are other ways to capture such cookies. For instance one could use malware to capture search traffic, but the simplest solution remains to search SID cookies.
Using a malware to redirect the traffic of infected computers through a proxy controlled by the attack would allow to capture session cookies. Such infection has recently been detected by Google which displayed a banner on its search page [1]. In that particular case, Google traffic redirection was merely a side effect which triggered the malware detection.
According to Google, a couple of millions of computers [1] were infected by this malware. Attackers could have captured a significant number of session cookies and run attacks described in our paper.
The simpler solution to find SID cookies is to search them. Typing the right query in Google provides a list of pages where people published captured HTTP traffic, including SID cookies (also works with Yahoo!).
If you replace your SID cookie by one of the cookies listed in these pages, you will receive the same personalized results than its owner. From these results you can quickly extract a list of visited results, Gmail contacts and Google+ acquaintances.
Not all these results contain full SID cookies and some of the listed SID cookies may have already expired, but this simple search should already provide many valid cookies to test the flaw. I’ve written a Chrome extension to simply replace the SID cookie for the “google.com” domain and quickly test different accounts. Once installed, click on the red button in the upper right corner, past the cookie value and click save.
On Firefox you could use the Web Developer extension to edit cookies (it does not seem to work on Firefox 5.0).
By publishing their (apparently innocuous) cookies users indirectly published part of their click-stream and associated it to their email address. Thus they established a public record of having visited these URLs [2], and this record is now linked to their name. From there, their full anonymized click-stream — not reduced to visited search results — could be de-anonymized by a tracking ad-network.
[1] Damian Menscher, “Using data to protect people from malware”, http://googleonlinesecurity.blogspot.com/2011/07/using-data-to-protect-people-from.html
[2] Arvind Narayanan, “There is no such thing as anonymous online tracking”, http://cyberlaw.stanford.edu/node/6701
Back in February, I re-discovered a small flaw in Google Search: result personalization leaks the list of results you clicked on. This leak was already known and mentioned in a paper by Castelluccia et al., but several features added by Google made it critical.
The third point has been addressed by Google very recently, when they introduced the new interface with the black top bar.
Vincent Verdot and I wrote a paper about this flaw. In order to conduct an experiment, we’ve been working on a proof of concept and an evaluation tool that we used to gather results.
This proof of concept is based on Firesheep (I just added a module and modify the attack launched when a SID cookie was captured). Firesheep is only working with the latest version of Firefox 3.6, do not expect to run it on Firefox 5.
With our version of Firesheep, when a Google SID cookie is captured, the account name appears in the Firesheep sidebar. Double clicking on it starts the attack; double clicking again displays the retrieved list of visited links.
We also designed a Firefox extension which downloads your web search history on your computer, issue a couple of search queries (mostly searching for extensions like: « .com, .fr, .us, .html, www, … ») and see how many clicked links can be retrieved.
We’ve run this experiment with a dozen of account and sent the result to Google. We’ll soon publish the paper as a technical report.
We’ve been in contact with Google Security Team who is working on a fix that should soon be deployed. In the meantime, make sure you’re not logged in your Google account when you’re connected on an unsecured network.
If you do not use Web Search History you may also purge it and disable the feature (visit https://www.google.com/history).
Also, TrackMeNot and Unsearch will reduce the exposition of your click history.
If you want to run the test 5 minutes:
Thanks for helping us.
Last year, I started to analyze Google Search and Google Suggest logs retention policies for the NYU Privacy Research Group meetings. To complete this analysis, I’m trying to review policies of other Google services.
While I just started this review, I noticed that Google seems to change the name of the section describing the recorded information. This section is either called:
My first understanding was that for services that require a Google Account to be used, Google uses the terms “Personal information” otherwise it uses “Information we collect”. But there are several exceptions. For instance, SafeBrowsing does not require an account to be used but Google TV does.
In addition, explicit references to server logs are made in these Personal Information sections while Google does not consider server logs as Personal Information (see their FAQ).
A loophole in Knol Privacy Policy allows Google to link your IP address and cookies to your user account. Knol (for Knowledge) is Google’s alternative to wikipedia. You need to have a Google account to contribute to Knol and — like most for Privacy Policy of Google services — Google mentions that it :
‘records information [your] account activity (e.g., storage usage, number of log-ins, actions taken), data displayed or clicked in the Knol interface […] and other log information (e.g., browser type, IP address, date and time of access, cookie ID, referrer URL). If you are logged in we may associate that information with your account.‘ [emphasis is mine]
This last sentence is unusual and suggest that if you ever logged in and visited Knol, Google can associate your IP address and Cookie IDs to your Goolge Account — and all the personal information attached to it. From that, Google can directly de-anonymized the searches you did when you were not logged in.
This loophole is certainly not intentional; this exact sentence appears in many privacy policies . As a matter of fact, this sentence also appears in YouTube and Blogger policies. Therefore we can assume that a same template has been used for services hosting user generated content.
However there are two big differences between Knol and Youtube or Blogger:
While not dramatic considering Knol relative lack of success, this mistake could have been more critical in the privacy policy of a more popular service.
Powered by sciolism 2019 and WordPress.